Μη-επιβλεπόμενη μηχανική μάθηση και ομαδοποίηση – Μέρος Γ: “K-mean clustering”
- Συγγραφέας: Σάββας Ράπτης
- 04-12-2021
- Δυσκολία: Δύσκολο
- Κατηγορίες: Τεχνολογίες
Η επιβλεπόμενη (supervised) μηχανική μάθηση που είδαμε στο δεύτερο μέρος, μοιάζει αρκετά με ότι κάναμε στο σχολείο όταν ήμασταν μικροί. Δηλαδή, ότι ο δάσκαλος γνώριζε πάντα τις απαντήσεις (labels) των προβλημάτων που μας έθετε. Μέσα από αυτή τη διαδικασία μαθαίνουμε να γενικεύουμε και να προβλέπουμε το αποτέλεσμα όταν μας δοθούν παρόμοια προβλήματα. Στη μη-επιβλεπόμενη (unsupervised) μάθηση, αντίθετα, έχουμε κάτι διαφορετικό. Εδώ ο υπολογιστής προσπαθεί να ανακαλύψει μοτίβα έτσι όπως ανακαλύπτουμε και εμείς στον κόσμο γύρω μας, δηλαδή παρατηρώντας και συγκρίνοντας πράγματα. Σε αντίθεση με ότι είδαμε μέχρι τώρα, στη μη-επιβλεπόμενη μάθηση δεν ξέρουμε την απάντηση, αλλά προσπαθούμε να τη βρούμε!
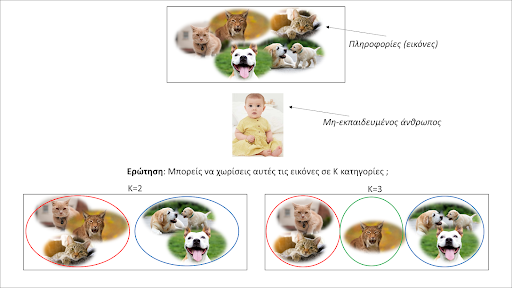
Ας δούμε αρχικά πώς εμείς οι άνθρωποι χρησιμοποιούμε μη-επιβλεπόμενη μάθηση (Εικόνα 1). Έστω ότι καλούμαστε να χωρίσουμε σε ομάδες τα ζώα που βλέπουμε στις εικόνες. Σε πόσες ομάδες θα τα χωρίζαμε; Όπως και ο μη-εκπαιδευμένος άνθρωπος (παιδί) που απεικονίζεται στην εικόνα, η απάντηση εξαρτάται από το πόσες κατηγορίες ψάχνουμε. Αν θέλαμε δύο κατηγορίες, θα λέγαμε ότι έχουμε σκύλους και γάτες. Αν όμως είχαμε τη δυνατότητα για τρεις θα ξεχωρίζαμε τη σκωτσέζικη αγριόγατα που δε μοιάζει και ιδιαίτερα με τις άλλες. Αυτό που κάναμε λέγεται επί της ουσίας μη-επιβλεπόμενη ομαδοποίηση (clustering), και ένας υπολογιστής, σαν εμάς, μπορεί να μάθει να το κάνει!
Ένας ιδιαίτερα διαδεδομένος αλγόριθμος που χρησιμοποιεί ο υπολογιστής για να κάνει τέτοιες διαδικασίες είναι ο K-mean! Το μόνο που χρειάζεται από εμάς είναι να του δώσουμε τα δεδομένα και τον αριθμό των ομάδων (“Κ”) που θέλουμε να χωρίσει1.
Πώς λειτουργεί όμως ο αλγόριθμος K-mean; Απλουστεύοντας, μπορούμε να χωρίσουμε τη διαδικασία σε δύο βήματα. Πρώτον, δίνουμε τον αριθμό των ομάδων που ψάχνουμε (Κ) και ο αλγόριθμος επιλέγει να φτιάξει Κ τυχαίες ομάδες. Στο επόμενο βήμα ο κώδικας προσπαθεί να διορθώσει το αποτέλεσμα (για την ώρα είναι απλώς τυχαίο). Συγκεκριμένα, χρησιμοποιεί το ότι ο μέσος όρος των στοιχείων μιας ομάδας πρέπει να βρίσκεται περίπου στη μέση των στοιχείων όταν αυτά είναι μαζεμένα κοντά το ένα στο άλλο. Για παράδειγμα, αν είχαμε μια ομάδα με 5 νούμερα, π.χ. 1,1,2,4,7, ο μέσος όρος τους είναι το 3 το οποίο είναι κοντά στη μέση της ομάδας μας.
Γνωρίζοντας αυτό λοιπόν ο αλγόριθμος κάνει το εξής τρικ. Επιλέγει να αλλάξει ομάδα σε κάθε ένα στοιχείο αναλόγως πόσο κοντά βρίσκεται στο μέσο όρο της κάθε ομάδας. Στη συνέχεια υπολογίζει εκ νέου τον μέσο όρο της κάθε μιας ξεχωριστά και αλλάζει τις ομάδες ξανά και ξανά μέχρι να σταθεροποιηθούν οι τιμές γύρω από έναν μέσο όρο. Έτσι μέσω αυτής της επανάληψης έχουμε τη διαδικασία “μάθησης”. Όμως η διαδικασία αυτή είναι πιο εύκολο να γίνει κατανοητή βλέποντάς τη στην πράξη στην Εικόνα 22!

Τέτοιοι αλγόριθμοι μπορούν ουσιαστικά να μας δώσουν δύο τύπου αποτελέσματα:
- Να χωρίσουν τα δεδομένα σε κατηγορίες που περιμέναμε και κατ’επέκταση να μας γλιτώσουν από χρόνο και κόπο σε σχέση με το να το κάναμε χειροκίνητα.
- Να μας βοηθήσουν να ανακαλύψουμε ομαδοποιήσεις που δεν είχαμε σκεφτεί προηγουμένως!
Στην καθημερινότητά μας, κώδικες παρόμοιοι με τον K-mean χρησιμοποιούνται συχνά. Για παράδειγμα, για να ξεχωρίσουμε πότε η χρήση μιας ιστοσελίδας γίνεται από κανονικό άνθρωπο και πότε από κάποιο πρόγραμμα! Στην αστροφυσική και διαστημική φυσική, οι κώδικες αυτοί έχουν επίσης εφαρμογές, όπως στην ταξινόμηση γαλαξιών σε κατηγορίες και στην αναγνώριση περιοχών της μαγνητόσφαιρας της Γης!
Περαιτέρω διάβασμα:
(Step 1 — Introduction) : Crashcourse — Unsupervised Learning: Crash Course AI #6 https://www.youtube.com/watch?v=JnnaDNNb380 & Crashcourse — Unsupervised Machine Learning: Crash Course Statistics #37 https://www.youtube.com/watch?v=IUn8k5zSI6g — StatQuest: K-means clustering https://www.youtube.com/watch?v=4b5d3muPQmA
(Step 2 — Hands-on) : Machine Learning Coursera Course | offered by Stanford: https://www.coursera.org/learn/machine-learning & Unsupervised Machine Learning | offered by IBM https://www.coursera.org/learn/ibm-unsupervised-machine-learning
(Step 3 — Theoretical reading) : Bishop, Christopher M. “Pattern Recognition and Machine Learning (Information Science and Statistics).” Machine learning 128.9 (2006). & list of books https://blog.floydhub.com/best-machine-learning-books/
1 Υπάρχουν και άλλες μέθοδοι μη-επιβλεπόμενης μάθησης που δε χρειάζεται να δώσουμε τον αριθμό των ομάδων. Σε αυτές τις τεχνικές γίνεται προσπάθεια να βρεθεί αλγοριθμικά ένας αριθμός, αλλά η διαδικασία που ακολουθούν είναι συνήθως πιο πολύπλοκη (βλέπε περαιτέρω διάβασμα).
2 Δοκίμασε και εσύ ακολουθώντας αυτόν το σύνδεσμο https://www.naftaliharris.com/blog/visualizing-k-means-clustering/ να δεις πως δουλεύει ο K-mean αλγόριθμος!