Ενισχυτική μάθηση – Μέρος Δ: “Γιατί οι υπολογιστές θα μας νικάνε για πάντα στα παιχνίδια;”
- Συγγραφέας: Σάββας Ράπτης
- 04-12-2021
- Δυσκολία: Μέτριο
- Κατηγορίες: Τεχνολογίες
Οι υπολογιστές έχουν τη δυνατότητα να μαθαίνουν, γενικεύοντας από ήδη γνωστές απαντήσεις (μέρος Β). Επίσης, μπορούν να ανακαλύπτουν μοτίβα και να ομαδοποιούν τις παρατηρήσεις όταν δεν έχουν γνωστές απαντήσεις (μέρος Γ). Όμως στη ζωή, τις περισσότερες φορές, αυτό που κάνει μέχρι και εμάς τους ανθρώπους να μάθουμε κάτι πραγματικά, είναι η διαδικασία “δοκιμής και σφάλματος” (trial and error). Δηλαδή δοκιμάζοντας πράγματα, αντιλαμβανόμαστε αν και κατά πόσο κάτι μας βοηθάει στην επίτευξη ενός στόχου, και αν όχι στρεφόμαστε σε κάτι διαφορετικό. Αυτό είναι το βασικό σκεπτικό πίσω από την ενισχυτική (reinforcement) μάθηση. Το πρώτο πράγμα που χρειαζόμαστε είναι ένα σύστημα κανόνων και μια σειρά δυνατών επιλογών. Στη συνέχεια καλούμαστε να δοκιμάσουμε τις επιλογές αυτές μέχρι να προκύψει η βέλτιστη αλληλουχία που μας φέρνει στο καλύτερο δυνατό αποτέλεσμα.
Συγκεκριμένα, στην ενισχυτική μάθηση έχουμε έναν υπολογιστή/πράκτορα (agent) που κάνει κάποιες κινήσεις (actions) στο χώρο (environment) που βρίσκεται. Όταν ο πράκτορας φτάσει σε κάποιο στόχο, τον επιβραβεύουμε (reward). Η επιβράβευση γίνεται παρατηρώντας ποιες κινήσεις έφεραν τον πράκτορα πιο κοντά στη νίκη και ουσιαστικά παροτρύνοντάς τον να προτιμά αυτές τις κινήσεις περισσότερο σε σχέση με τις υπόλοιπες δυνατές στο μέλλον.
Όμως, όλη αυτή η ορολογία γίνεται πιο κατανοητή με ένα παράδειγμα (Εικόνα 1). Ένας πράκτορας (ρομποτάκι) έχει δυνατές επιλογές να κινηθεί δεξιά, αριστερά, πάνω και κάτω σε ένα προκατασκευασμένο χώρο, με στόχο να φτάσει την μπαταρία. Οπότε το αφήνουμε να κινηθεί ελεύθερα στο χώρο μέχρι κάποια στιγμή να τα καταφέρει και να απολαύσει την πολύτιμη ενέργεια της μπαταρίας (επιβράβευση)!
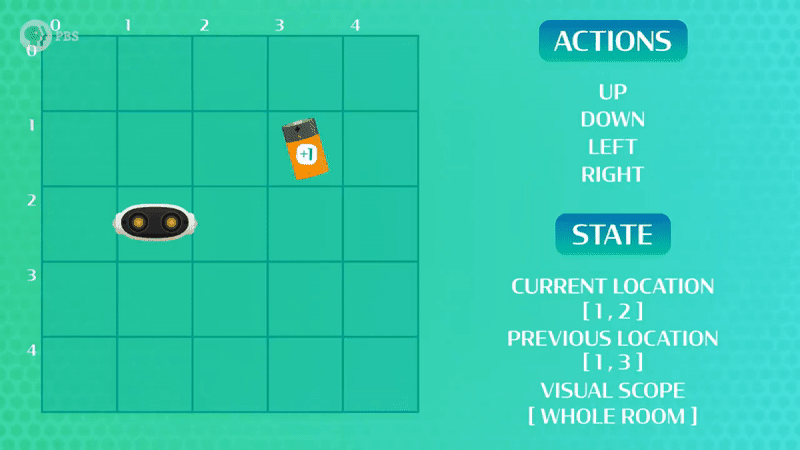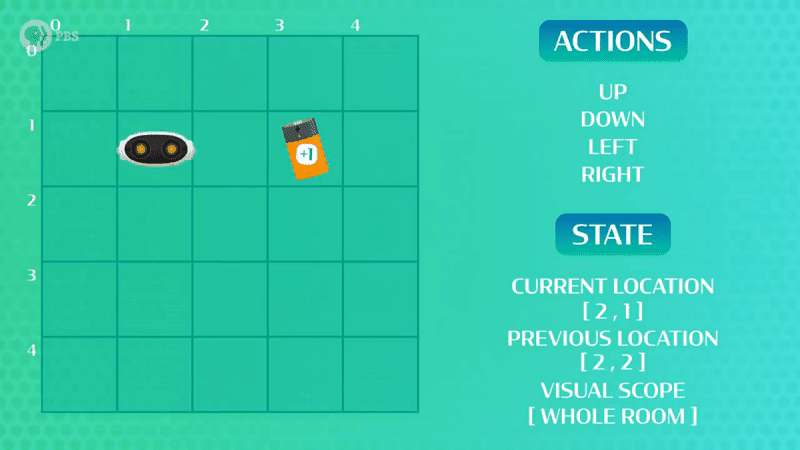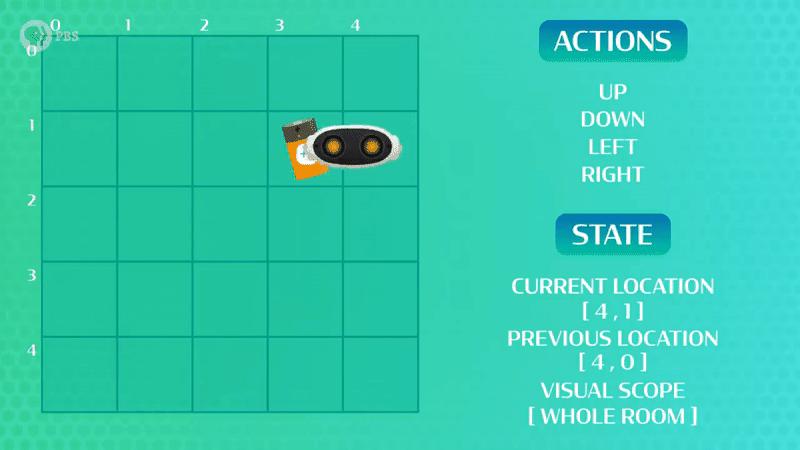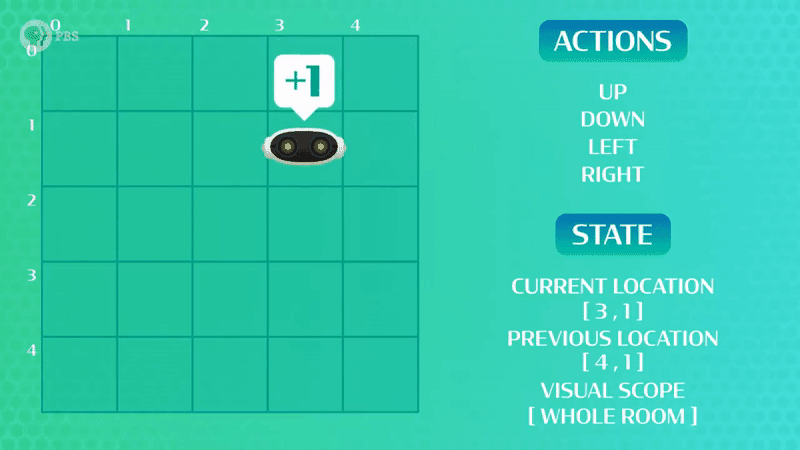
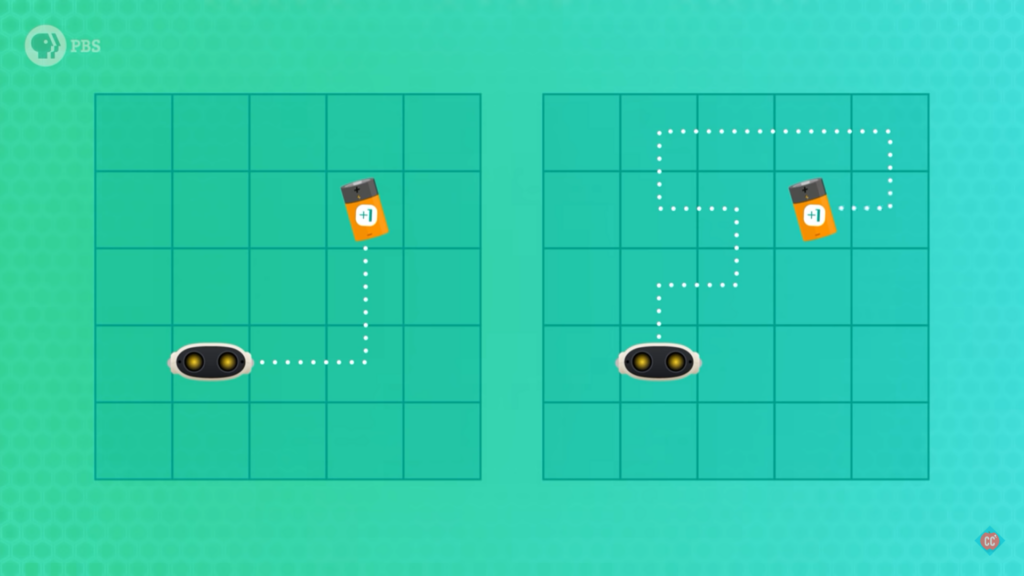
Παρόλο που κατάφερε να φτάσει στην μπαταρία το ρομπότ μας, βλέπουμε ότι δεν έκανε τη βέλτιστη διαδρομή! Πολλές φορές στην ενισχυτική μάθηση, όπως και στο παράδειγμά μας, χρειάζεται ο πράκτοράς μας να βρει μια πιο καλή λύση. Σε αυτή την περίπτωση επαναλαμβάνουμε τη διαδικασία ώστε να εξερευνήσουμε και άλλες δυνατές επιλογές, που ίσως μας φέρουν πιο γρήγορα στον στόχο! Στην περίπτωση που εξετάζουμε, το ρομπότ ψάχνει να βρει την μπαταρία ξανά και ξανά (εκπαίδευση) μέχρι να εκπαιδευτεί και να βρει την πιο σύντομη διαδρομή (Βλέπε Εικόνα 2 – Αριστερά)!
Σήμερα, ακολουθώντας αυτές τις βασικές αρχές σε όλο και πιο πολύπλοκα προβλήματα, έχουμε υπολογιστές που μπορούν και φέρνουν εις πέρας διαδικασίες πολύ πιο αποδοτικά από εμάς τους ανθρώπους. Όπως είδαμε και στο μέρος Α, το 2017, στο επιτραπέζιο Go, ο υπολογιστής AlphaGo νίκησε τον παγκόσμιο πρωταθλητή Ke Jie! Επίσης, ακόμα και σε ομαδικά βιντεοπαιχνίδια όπως το DOTA 2, ο υπολογιστής της OpenAI νίκησε με ευκολία τους παγκόσμιους πρωταθλητές (2018 και 2019) OG! Πέρα όμως από ψηφιακές εφαρμογές, με τη μέθοδο της ενισχυτικής μάθησης, μπορούμε να εκπαιδεύσουμε ρομπότ να περπατούν και να τρέχουν (βλέπε εικόνα 3) ή ακόμα και αυτοκίνητα να κινούνται μόνα τους, χωρίς την παρουσία οδηγού (self-driving cars)!

Περαιτέρω διάβασμα:
(Step 1 — Introduction) : Crashcourse — Reinforcement Learning: Crash Course AI#9 https://www.youtube.com/watch?v=nIgIv4IfJ6s&t & Arxiv Insights — An introduction to Reinforcement Learning https://www.youtube.com/watch?v=JgvyzIkgxF0
(Step 2 — Hands-on & Advanced lectures) : Fundamentals of Reinforcement Learning | offered by University of Alberta: https://www.coursera.org/learn/fundamentals-of-reinforcement-learning, Reinforcement Learning Specialization | offered by university of Alberta https://www.coursera.org/specializations/reinforcement-learning & MIT 6.S191 (2020): Reinforcement Learning https://www.youtube.com/watch?v=nZfaHIxDD5w
(Step 3 — Theoretical reading) : Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018.